
We present a novel part-aware generative model for editable 3D shape synthesis. In contrast to prior works, our method does not require any explicit 3D or part supervision and is able to produce textures. Our model generates objects as a set of locally defined NeRFs, augmented with an affine transformation. This enables several editing operations such as applying transformations on parts, mixing parts from different objects etc. To ensure distinct, manipulable parts we enforce a hard assignment of rays to parts that makes sure that the color of each ray is only determined by a single NeRF. As a result, altering one part does not affect the appearance of the others.
Our goal is to design a 3D part-aware generative model that can be trained without explicit 3D supervision. Moreover, we want our generated shapes to be editable, namely to be able to make local changes on the shape and texture of specific parts of the object. To this end, we represent objects using $M$ locally defined parts that are parametrized with a NeRF. Defining NeRFs locally, i.e. in their own coordinate system, enables direct part-level control simply by applying transformations on the per-part coordinate system. However, to achieve distinct, manipulable parts, it is essential that each object part is represented by a single NeRF. To enforce this, we introduce a hard assignment between rays and parts by associating a ray with the first part it intersects. Namely, the color of each ray is predicted from a single NeRF, thus preventing combinations of parts reasoning about the color of a ray. This ensures that when editing one part, the shape and appearance of the others does not change.
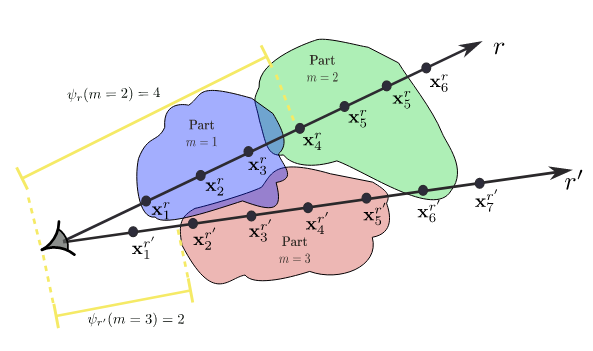
We illustrate the hard assignment between rays and parts in a 2D example with 3 parts and two rays $r$ and $r'$. Since the association between rays and parts is determined based on the first part that a ray interests, the associations that emerge are $\mathcal{R}_1=\{r\}$, $\mathcal{R}_2=\varnothing$ and $\mathcal{R}_3=\{r'\}$.

Our generative model is implemented as an auto-decoder and it comprises three main components: The Decomposition Network takes two object specific learnable embeddings $\{\mathbf{z}_s, \mathbf{z}_t\}$ that represent its shape and texture and maps them to a set of $M$ latent codes that control the shape and texture of each part. First, we map $\mathbf{z}^s$ and $\mathbf{z}^t$ to $M$ per-part embeddings $\{\hat{\mathbf{z}}_m^s\}_{m=1}^M$ and $\{\hat{\mathbf{z}}_m^t\}_{m=1}^M$ using $M$ linear projections, which are then fed to two transformer encoders: $\tau^s_\theta$ and $\tau^t_\theta$, that predict the final per-part shape and texture embeddings, $\{\mathbf{z}_m^s\}_{m=1}^M$ and $\{\mathbf{z}_m^t\}_{m=1}^M$. Next, the Structure Network maps the per-part shape feature representation $\mathbf{z}_m^s$ to a rotation matrix $\mathbf{R}_m$, a translation vector $\mathbf{t}_m$ and a scale vector $\mathbf{s}_m$ that define the coordinate system of the m-th part and its spatial extent. The last component of our model is the Neural Rendering module that takes the 3D points along each ray, transformed to the coordinate frame of its associated part, and maps them to an occupancy and a color value. We use plate notation to denote repetition over the $M$ parts.
We showcase editing results on a specific scene using our method, overfitting on the NeRF Lego dataset. The first example depicts renderings of novel views, before editing. In the second example, we rotate the bucket downwards, while in the third example we translate the cockpit to the floor. In the fourth and fifth examples, we show part scaling editing operations, increasing and decreasing the size of the cockpit respectively. In the last example, we select the bucket and change its color to red.
Our model can be used to mix parts of 3D objects, forming new 3D objects. The following figure showcases geometry and texture mixing operations. We mix parts from two shapes (columns 1, 2), and show geometry (column 3), texture (column 4), and combined geometry and texture mixing (column 5). The first and third rows contain image renders, while the second and fourth rows contain the corresponding geometry. Selected parts are colored in green.
Our model can be used to generate new 3D objects, sampling latent codes drawn from the distribution of the learned per-instance shape embeddings. Examples of generated airplanes, cars and chairs are presented below.
We showcase examples of editing operations. A user can select the parts corresponding to the tail of an airplane and move them forward and backward. Similarly, the wings of another airplane can be selected and translated accordingly. The third example showcases colorizing specific parts of a chair. In the fourth example we select and scale the parts corresponding to the wheels of the truck. Finally, we keep the camera pose fixed, and translate all the car parts, moving the car in the scene.
This research was supported by an ARL grant W911NF-21-2-0104 and an Adobe research gift. Konstantinos Tertikas and Ioannis Emiris have received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 860843. Despoina Paschalidou is supported by the Swiss National Science Foundation under grant number P500PT_206946. Leonidas Guibas is supported by a Vannevar Bush Faculty Fellowship.
@inproceedings{Tertikas2023CVPR,
author = {Tertikas, Konstantinos and Paschalidou, Despoina and Pan, Boxiao and Park, Jeong Joon and Uy, Mikaela Angelina and Emiris, Ioannis and Avrithis, Yannis and Guibas, Leonidas},
title = {Generating Part-Aware Editable 3D Shapes without 3D Supervision},
booktitle = {Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year = {2023}
}











































